| 全缓冲、行缓冲、无缓冲三种缓冲区的理解 | 您所在的位置:网站首页 › 盛开write as › 全缓冲、行缓冲、无缓冲三种缓冲区的理解 |
全缓冲、行缓冲、无缓冲三种缓冲区的理解
|
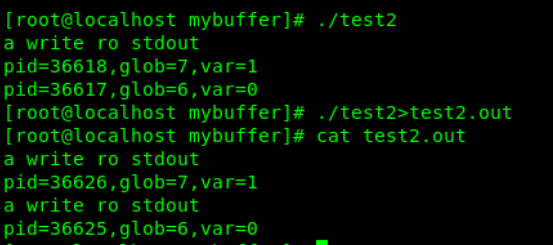
缓冲区又称为缓存,它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。 缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。 为什么要引入缓冲区 比如我们从磁盘里取信息,我们先把读出的数据放在缓冲区,计算机再直接从缓冲区中取数据,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度。 又比如,当计算机的高速部件与低速部件通讯时,必须将高速部件的输出暂存到某处,以保证高速部件与低速部件相吻合。通常情况下,就是为了高效的处理我们的cpu和i/o设备之间的交互,因为我们知道cpu处理速度是很快的。举个例子,电脑的cpu通常情况下要处理很多事务,而我们从键盘敲下的文字相对于cpu的处理是很慢的,cpu不能老等着我们,它可以这时候去处理别的事务。所以当我们敲小的文字被先放到了缓冲区,等待cpu最后的统一处理。这样就让计算机的cpu变得高效起来。 说白了,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。 缓冲区的类型 缓冲区 分为三种类型:全缓冲、行缓冲和不带缓冲。 全缓冲 在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写。 行缓冲 在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作。这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作。典型代表是标准输入(stdin)和标准输出(stdout)。 不带缓冲 也就是不进行缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来。 1、验证代码如下: #include #include int glob=6; char buf[]="a write ro stdout\n"; int main() { int var; pid_t pid; printf(buf); // fflush(NULL);//fllush(NULL)刷新所有的文件更新 if((pid=fork()) if(pid==0) { glob++; var++; } else { sleep(2); } } printf("pid=%d,glob=%d,var=%d\n",getpid(),glob,var); exit(0); }结果如下:
验证全缓冲区满了才会真正执行执行i/o操作,验证程序如下: #include #include int main(int argc, char *argv[]){ FILE *fp = NULL; // 读写方式打开,文件不存在则创建 fp = fopen("demo2.txt", "w+"); if(NULL == fp) { printf("open error\n"); return 1; } char *str = "hello demo2\n"; int i = 0; while(i |
 如果我们没有自己设置缓冲区的话,系统会默认为标准输入输出设置一个缓冲区,这个缓冲区的大小通常是512个字节的大小。
如果我们没有自己设置缓冲区的话,系统会默认为标准输入输出设置一个缓冲区,这个缓冲区的大小通常是512个字节的大小。【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |